上海交大王国兴团队研发出高能效脉冲神经网络加速器芯片,为类脑计算与边缘智能注入新动能
上海交通大学微纳电子学系王国兴教授团队在高能效脉冲神经网络加速器芯片研发上取得突破性进展。该成果为类脑计算从理论走向实用、特别是满足边缘侧设备对实时智能处理的严苛需求,提供了关键的硬件基础,标志着我国在网络技术,特别是新兴的神经形态计算领域的前沿探索迈出了坚实一步。
脉冲神经网络,作为第三代人工神经网络模型,其灵感直接源于生物大脑的运作机制。与传统人工神经网络不同,SNN以离散的脉冲序列来编码和传递信息,具有事件驱动、稀疏计算等天然特性,理论上能实现远高于传统架构的能效比。如何将这一理论优势在硬件上高效实现,一直是学术界和产业界面临的核心挑战。
王国兴团队此次研发的SNN加速器芯片,正是针对这一核心挑战提出的创新解决方案。该芯片在架构和电路层面进行了协同优化设计,主要体现在以下几个方面:
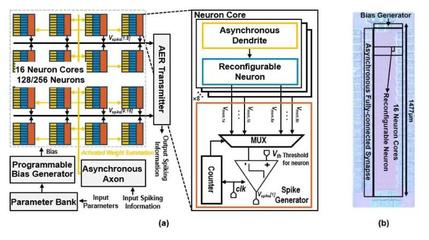
团队提出了创新的稀疏事件驱动处理架构。传统计算架构即使在没有有效数据时,时钟和计算单元也持续运行,造成大量功耗浪费。而该芯片实现了真正的“有事件才工作”模式,能够动态识别并跳过输入和网络内部的零激活(无脉冲)数据,仅对有效的脉冲事件进行路由和计算,从根本上消除了静态功耗和无效计算开销。
团队设计了高并行度的脉冲事件处理引擎。为了应对脉冲事件在时间和空间上的随机性,芯片内部集成了多组高度并行的计算核心,能够同时处理多个突触连接和神经元状态更新。这种设计确保了即使在事件密集时段,芯片也能维持高吞吐量和低延迟,满足实时处理的要求。
芯片采用了近内存计算技术。通过将计算单元紧密嵌入到存储突触权重的存储阵列附近,极大地减少了数据在计算核心与内存之间频繁搬移所产生的巨大能耗(即“内存墙”问题)。这种设计显著提升了数据访问效率,是达成高能效的关键一环。
据团队公布的测试数据,该加速器芯片在典型视觉分类与目标检测等SNN任务上,展现了卓越的性能功耗比。其能效比显著优于传统的基于冯·诺依曼架构的GPU/CPU平台,甚至优于一些已报道的专用神经网络加速器,为在电池供电的物联网终端、移动设备、可穿戴设备以及嵌入式视觉系统中部署复杂的实时智能算法提供了可能。
这项进展的深远意义在于,它不仅仅是一项芯片技术的突破,更是为边缘人工智能的发展铺平了道路。随着5G和物联网的普及,海量数据在边缘侧产生,将计算智能下沉至边缘设备,而非全部上传至云端,是降低延迟、保护隐私、节约带宽的必然趋势。王国兴团队的高能效SNN芯片,正是契合了这一趋势,使得在资源受限的边缘设备上运行复杂的类脑智能模型成为现实。
该成果也推动了类脑计算的实用化进程。类脑计算被视为突破现有AI算力与能效瓶颈的重要方向之一。这款芯片的成功研制,证明了基于脉冲神经网络的硬件方案在能效上的巨大潜力,为未来开发更大规模、更接近生物脑处理机制的智能计算系统奠定了重要的技术基础。
可以预见,随着此类专用硬件的不断成熟,脉冲神经网络将在自动驾驶、智能传感、机器人控制、智能家居等对实时性与能效要求极高的领域发挥越来越重要的作用。上海交大王国兴团队的这一重要进展,是我国在下一代人工智能计算核心技术竞争中取得的又一突出成果,展现了我国科研工作者在前沿交叉领域的创新实力。
如若转载,请注明出处:http://www.lijuantong.com/product/71.html
更新时间:2026-06-18 05:39:24